Kubernetes Grundlagen
Tip
Lerne & übe AWS Hacking:
HackTricks Training AWS Red Team Expert (ARTE)
Lerne & übe GCP Hacking:HackTricks Training GCP Red Team Expert (GRTE)
Lerne & übe Az Hacking:HackTricks Training Azure Red Team Expert (AzRTE)
Unterstütze HackTricks
- Sieh dir die Abonnementpläne an!
- Tritt der 💬 Discord group oder der telegram group bei oder folge uns auf Twitter 🐦 @hacktricks_live.
- Teile Hacking-Tricks, indem du PRs an die HackTricks und HackTricks Cloud GitHub-Repos einreichst.
Der ursprüngliche Autor dieser Seite ist Jorge (lesen Sie seinen ursprünglichen Beitrag hier)
Architektur & Grundlagen
Was macht Kubernetes?
- Ermöglicht das Ausführen von Containern in einer Container-Engine.
- Der Scheduler ermöglicht eine effiziente Planung von Containern.
- Hält Container am Leben.
- Ermöglicht die Kommunikation zwischen Containern.
- Ermöglicht Bereitstellungstechniken.
- Verarbeitet große Datenmengen.
Architektur
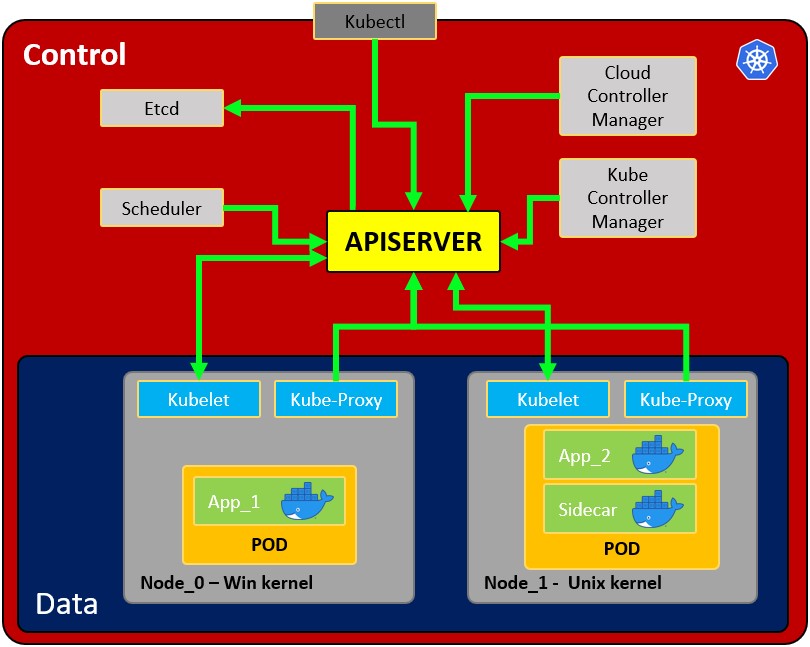
- Node: Betriebssystem mit Pod oder Pods.
- Pod: Wrapper um einen Container oder mehrere Container. Ein Pod sollte nur eine Anwendung enthalten (normalerweise läuft ein Pod nur 1 Container). Der Pod ist die Art und Weise, wie Kubernetes die Containertechnologie abstrahiert.
- Service: Jeder Pod hat 1 interne IP-Adresse aus dem internen Bereich des Nodes. Er kann jedoch auch über einen Service exponiert werden. Der Service hat ebenfalls eine IP-Adresse und sein Ziel ist es, die Kommunikation zwischen Pods aufrechtzuerhalten, sodass, wenn einer ausfällt, der neue Ersatz (mit einer anderen internen IP) über die gleiche IP des Services zugänglich ist. Er kann als intern oder extern konfiguriert werden. Der Service fungiert auch als Lastenausgleich, wenn 2 Pods mit demselben Service verbunden sind.
Wenn ein Service erstellt wird, können Sie die Endpunkte jedes Services mitkubectl get endpointsfinden. - Kubelet: Primärer Node-Agent. Die Komponente, die die Kommunikation zwischen Node und kubectl herstellt und nur Pods ausführen kann (über den API-Server). Der Kubelet verwaltet keine Container, die nicht von Kubernetes erstellt wurden.
- Kube-proxy: ist der Service, der für die Kommunikation (Services) zwischen dem apiserver und dem Node verantwortlich ist. Die Basis ist ein IPtables für Nodes. Erfahrene Benutzer könnten andere Kube-Proxys von anderen Anbietern installieren.
- Sidecar-Container: Sidecar-Container sind die Container, die zusammen mit dem Hauptcontainer im Pod ausgeführt werden sollten. Dieses Sidecar-Muster erweitert und verbessert die Funktionalität der aktuellen Container, ohne sie zu ändern. Heutzutage wissen wir, dass wir Containertechnologie verwenden, um alle Abhängigkeiten für die Anwendung zu verpacken, damit sie überall ausgeführt werden kann. Ein Container macht nur eine Sache und macht diese Sache sehr gut.
- Master-Prozess:
- Api Server: Ist der Weg, wie die Benutzer und die Pods mit dem Master-Prozess kommunizieren. Nur authentifizierte Anfragen sollten erlaubt sein.
- Scheduler: Die Planung bezieht sich darauf, sicherzustellen, dass Pods den Nodes zugeordnet werden, damit Kubelet sie ausführen kann. Er hat genug Intelligenz, um zu entscheiden, welcher Node mehr verfügbare Ressourcen hat, um den neuen Pod zuzuweisen. Beachten Sie, dass der Scheduler keine neuen Pods startet, sondern nur mit dem Kubelet-Prozess kommuniziert, der im Node läuft und den neuen Pod startet.
- Kube Controller Manager: Er überprüft Ressourcen wie Replica-Sets oder Deployments, um zu überprüfen, ob beispielsweise die richtige Anzahl von Pods oder Nodes läuft. Falls ein Pod fehlt, kommuniziert er mit dem Scheduler, um einen neuen zu starten. Er steuert Replikation, Tokens und Kontodienste für die API.
- etcd: Datenspeicher, persistent, konsistent und verteilt. Ist die Datenbank von Kubernetes und der Schlüssel-Wert-Speicher, in dem der vollständige Zustand der Cluster gespeichert wird (jede Änderung wird hier protokolliert). Komponenten wie der Scheduler oder der Controller Manager sind auf diese Daten angewiesen, um zu wissen, welche Änderungen aufgetreten sind (verfügbare Ressourcen der Nodes, Anzahl der laufenden Pods…).
- Cloud Controller Manager: Ist der spezifische Controller für Flusskontrollen und Anwendungen, d.h.: wenn Sie Cluster in AWS oder OpenStack haben.
Beachten Sie, dass es mehrere Nodes (die mehrere Pods ausführen) geben kann, und es kann auch mehrere Master-Prozesse geben, deren Zugriff auf den Api-Server lastenausgeglichen und deren etcd synchronisiert ist.
Volumes:
Wenn ein Pod Daten erstellt, die nicht verloren gehen sollten, wenn der Pod verschwindet, sollten sie in einem physischen Volume gespeichert werden. Kubernetes ermöglicht es, ein Volume an einen Pod anzuhängen, um die Daten zu persistieren. Das Volume kann auf der lokalen Maschine oder in einem Remote-Speicher sein. Wenn Sie Pods auf verschiedenen physischen Nodes ausführen, sollten Sie einen Remote-Speicher verwenden, damit alle Pods darauf zugreifen können.
Weitere Konfigurationen:
- ConfigMap: Sie können URLs konfigurieren, um auf Services zuzugreifen. Der Pod wird hier Daten abrufen, um zu wissen, wie er mit den anderen Services (Pods) kommunizieren kann. Beachten Sie, dass dies nicht der empfohlene Ort ist, um Anmeldeinformationen zu speichern!
- Secret: Dies ist der Ort, um geheime Daten wie Passwörter, API-Schlüssel… in B64 kodiert zu speichern. Der Pod kann auf diese Daten zugreifen, um die erforderlichen Anmeldeinformationen zu verwenden.
- Deployments: Hier werden die Komponenten angegeben, die von Kubernetes ausgeführt werden sollen. Ein Benutzer arbeitet normalerweise nicht direkt mit Pods, Pods sind in ReplicaSets abstrahiert (Anzahl der gleichen Pods, die repliziert werden), die über Deployments ausgeführt werden. Beachten Sie, dass Deployments für zustandslose Anwendungen gedacht sind. Die minimale Konfiguration für ein Deployment ist der Name und das auszuführende Image.
- StatefulSet: Diese Komponente ist speziell für Anwendungen wie Datenbanken gedacht, die auf denselben Speicher zugreifen müssen.
- Ingress: Dies ist die Konfiguration, die verwendet wird, um die Anwendung öffentlich mit einer URL exponieren. Beachten Sie, dass dies auch mit externen Services erfolgen kann, aber dies ist der richtige Weg, um die Anwendung zu exponieren.
- Wenn Sie ein Ingress implementieren, müssen Sie Ingress-Controller erstellen. Der Ingress-Controller ist ein Pod, der der Endpunkt sein wird, der die Anfragen empfängt, überprüft und sie an die Services lastenausgleicht. Der Ingress-Controller wird die Anfrage basierend auf den konfigurierten Ingress-Regeln senden. Beachten Sie, dass die Ingress-Regeln auf verschiedene Pfade oder sogar Subdomains zu verschiedenen internen Kubernetes-Services verweisen können.
- Eine bessere Sicherheitspraktik wäre es, einen Cloud-Lastenausgleich oder einen Proxy-Server als Einstiegspunkt zu verwenden, um keinen Teil des Kubernetes-Clusters exponiert zu haben.
- Wenn eine Anfrage empfangen wird, die keiner Ingress-Regel entspricht, wird der Ingress-Controller sie an den “Default backend” weiterleiten. Sie können den Ingress-Controller
describeverwenden, um die Adresse dieses Parameters zu erhalten. minikube addons enable ingress
PKI-Infrastruktur - Zertifizierungsstelle CA:
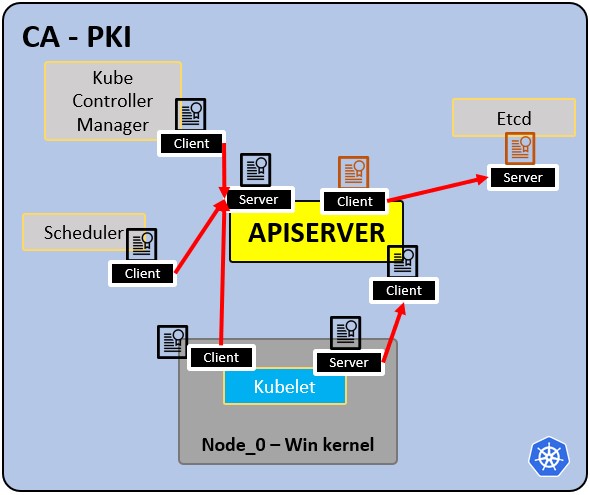
- CA ist die vertrauenswürdige Wurzel für alle Zertifikate innerhalb des Clusters.
- Ermöglicht es Komponenten, sich gegenseitig zu validieren.
- Alle Clusterzertifikate sind von der CA signiert.
- etcd hat sein eigenes Zertifikat.
- Typen:
- apiserver-Zertifikat.
- kubelet-Zertifikat.
- scheduler-Zertifikat.
Grundlegende Aktionen
Minikube
Minikube kann verwendet werden, um einige schnelle Tests auf Kubernetes durchzuführen, ohne eine vollständige Kubernetes-Umgebung bereitstellen zu müssen. Es wird die Master- und Node-Prozesse auf einer Maschine ausführen. Minikube verwendet VirtualBox, um den Node auszuführen. Siehe hier, wie man es installiert.
$ minikube start
😄 minikube v1.19.0 on Ubuntu 20.04
✨ Automatically selected the virtualbox driver. Other choices: none, ssh
💿 Downloading VM boot image ...
> minikube-v1.19.0.iso.sha256: 65 B / 65 B [-------------] 100.00% ? p/s 0s
> minikube-v1.19.0.iso: 244.49 MiB / 244.49 MiB 100.00% 1.78 MiB p/s 2m17.
👍 Starting control plane node minikube in cluster minikube
💾 Downloading Kubernetes v1.20.2 preload ...
> preloaded-images-k8s-v10-v1...: 491.71 MiB / 491.71 MiB 100.00% 2.59 MiB
🔥 Creating virtualbox VM (CPUs=2, Memory=3900MB, Disk=20000MB) ...
🐳 Preparing Kubernetes v1.20.2 on Docker 20.10.4 ...
▪ Generating certificates and keys ...
▪ Booting up control plane ...
▪ Configuring RBAC rules ...
🔎 Verifying Kubernetes components...
▪ Using image gcr.io/k8s-minikube/storage-provisioner:v5
🌟 Enabled addons: storage-provisioner, default-storageclass
🏄 Done! kubectl is now configured to use "minikube" cluster and "default" namespace by defaul
$ minikube status
host: Running
kubelet: Running
apiserver: Running
kubeconfig: Configured
---- ONCE YOU HAVE A K8 SERVICE RUNNING WITH AN EXTERNAL SERVICE -----
$ minikube service mongo-express-service
(This will open your browser to access the service exposed port)
$ minikube delete
🔥 Deleting "minikube" in virtualbox ...
💀 Removed all traces of the "minikube" cluster
Kubectl Grundlagen
Kubectl ist das Befehlszeilenwerkzeug für Kubernetes-Cluster. Es kommuniziert mit dem API-Server des Master-Prozesses, um Aktionen in Kubernetes auszuführen oder um Daten anzufordern.
kubectl version #Get client and server version
kubectl get pod
kubectl get services
kubectl get deployment
kubectl get replicaset
kubectl get secret
kubectl get all
kubectl get ingress
kubectl get endpoints
#kubectl create deployment <deployment-name> --image=<docker image>
kubectl create deployment nginx-deployment --image=nginx
#Access the configuration of the deployment and modify it
#kubectl edit deployment <deployment-name>
kubectl edit deployment nginx-deployment
#Get the logs of the pod for debbugging (the output of the docker container running)
#kubectl logs <replicaset-id/pod-id>
kubectl logs nginx-deployment-84cd76b964
#kubectl describe pod <pod-id>
kubectl describe pod mongo-depl-5fd6b7d4b4-kkt9q
#kubectl exec -it <pod-id> -- bash
kubectl exec -it mongo-depl-5fd6b7d4b4-kkt9q -- bash
#kubectl describe service <service-name>
kubectl describe service mongodb-service
#kubectl delete deployment <deployment-name>
kubectl delete deployment mongo-depl
#Deploy from config file
kubectl apply -f deployment.yml
Minikube Dashboard
Das Dashboard ermöglicht es Ihnen, einfacher zu sehen, was Minikube ausführt. Sie finden die URL, um darauf zuzugreifen, in:
minikube dashboard --url
🔌 Enabling dashboard ...
▪ Using image kubernetesui/dashboard:v2.3.1
▪ Using image kubernetesui/metrics-scraper:v1.0.7
🤔 Verifying dashboard health ...
🚀 Launching proxy ...
🤔 Verifying proxy health ...
http://127.0.0.1:50034/api/v1/namespaces/kubernetes-dashboard/services/http:kubernetes-dashboard:/proxy/
YAML-Konfigurationsdateien Beispiele
Jede Konfigurationsdatei hat 3 Teile: Metadaten, Spezifikation (was gestartet werden muss), Status (gewünschter Zustand).
Innerhalb der Spezifikation der Bereitstellungs-Konfigurationsdatei finden Sie die Vorlage, die mit einer neuen Konfigurationsstruktur definiert ist, die das auszuführende Image definiert:
Beispiel für Bereitstellung + Dienst, die in derselben Konfigurationsdatei deklariert sind (von hier)
Da ein Dienst normalerweise mit einer Bereitstellung verbunden ist, ist es möglich, beide in derselben Konfigurationsdatei zu deklarieren (der in dieser Konfiguration deklarierte Dienst ist nur intern zugänglich):
apiVersion: apps/v1
kind: Deployment
metadata:
name: mongodb-deployment
labels:
app: mongodb
spec:
replicas: 1
selector:
matchLabels:
app: mongodb
template:
metadata:
labels:
app: mongodb
spec:
containers:
- name: mongodb
image: mongo
ports:
- containerPort: 27017
env:
- name: MONGO_INITDB_ROOT_USERNAME
valueFrom:
secretKeyRef:
name: mongodb-secret
key: mongo-root-username
- name: MONGO_INITDB_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mongodb-secret
key: mongo-root-password
---
apiVersion: v1
kind: Service
metadata:
name: mongodb-service
spec:
selector:
app: mongodb
ports:
- protocol: TCP
port: 27017
targetPort: 27017
Beispiel für die Konfiguration eines externen Dienstes
Dieser Dienst wird extern zugänglich sein (überprüfen Sie die Attribute nodePort und type: LoadBlancer):
---
apiVersion: v1
kind: Service
metadata:
name: mongo-express-service
spec:
selector:
app: mongo-express
type: LoadBalancer
ports:
- protocol: TCP
port: 8081
targetPort: 8081
nodePort: 30000
Note
Dies ist nützlich für Tests, aber für die Produktion sollten Sie nur interne Dienste und ein Ingress haben, um die Anwendung bereitzustellen.
Beispiel einer Ingress-Konfigurationsdatei
Dies wird die Anwendung unter http://dashboard.com bereitstellen.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: dashboard-ingress
namespace: kubernetes-dashboard
spec:
rules:
- host: dashboard.com
http:
paths:
- backend:
serviceName: kubernetes-dashboard
servicePort: 80
Beispiel einer Geheimnisse-Konfigurationsdatei
Beachten Sie, wie das Passwort in B64 codiert ist (was nicht sicher ist!)
apiVersion: v1
kind: Secret
metadata:
name: mongodb-secret
type: Opaque
data:
mongo-root-username: dXNlcm5hbWU=
mongo-root-password: cGFzc3dvcmQ=
Beispiel für ConfigMap
Eine ConfigMap ist die Konfiguration, die den Pods gegeben wird, damit sie wissen, wie sie andere Dienste finden und darauf zugreifen können. In diesem Fall wird jeder Pod wissen, dass der Name mongodb-service die Adresse eines Pods ist, mit dem sie kommunizieren können (dieser Pod wird ein mongodb ausführen):
apiVersion: v1
kind: ConfigMap
metadata:
name: mongodb-configmap
data:
database_url: mongodb-service
Dann kann diese Adresse innerhalb einer deployment config folgendermaßen angegeben werden, damit sie in die Umgebungsvariablen des Pods geladen wird:
[...]
spec:
[...]
template:
[...]
spec:
containers:
- name: mongo-express
image: mongo-express
ports:
- containerPort: 8081
env:
- name: ME_CONFIG_MONGODB_SERVER
valueFrom:
configMapKeyRef:
name: mongodb-configmap
key: database_url
[...]
Beispiel für die Volumen-Konfiguration
Sie finden verschiedene Beispiele für Speicher-Konfigurations-YAML-Dateien in https://gitlab.com/nanuchi/youtube-tutorial-series/-/tree/master/kubernetes-volumes.
Beachten Sie, dass Volumes nicht innerhalb von Namespaces sind
Namespaces
Kubernetes unterstützt mehrere virtuelle Cluster, die von demselben physischen Cluster unterstützt werden. Diese virtuellen Cluster werden Namespaces genannt. Sie sind für den Einsatz in Umgebungen mit vielen Benutzern, die über mehrere Teams oder Projekte verteilt sind, gedacht. Für Cluster mit wenigen bis mehreren Dutzend Benutzern sollten Sie keine Namespaces erstellen oder darüber nachdenken müssen. Sie sollten nur beginnen, Namespaces zu verwenden, um eine bessere Kontrolle und Organisation jedes Teils der in Kubernetes bereitgestellten Anwendung zu haben.
Namespaces bieten einen Geltungsbereich für Namen. Die Namen von Ressourcen müssen innerhalb eines Namespaces eindeutig sein, jedoch nicht über Namespaces hinweg. Namespaces können nicht ineinander geschachtelt werden und jede Kubernetes Ressource kann nur in einem Namespace sein.
Es gibt standardmäßig 4 Namespaces, wenn Sie Minikube verwenden:
kubectl get namespace
NAME STATUS AGE
default Active 1d
kube-node-lease Active 1d
kube-public Active 1d
kube-system Active 1d
- kube-system: Es ist nicht für die Benutzer gedacht und Sie sollten es nicht anfassen. Es ist für Master- und kubectl-Prozesse.
- kube-public: Öffentlich zugängliche Daten. Enthält ein ConfigMap, das Clusterinformationen enthält.
- kube-node-lease: Bestimmt die Verfügbarkeit eines Knotens.
- default: Der Namespace, den der Benutzer verwenden wird, um Ressourcen zu erstellen.
#Create namespace
kubectl create namespace my-namespace
Note
Beachten Sie, dass die meisten Kubernetes-Ressourcen (z. B. Pods, Dienste, Replikationscontroller und andere) in einigen Namespaces sind. Andere Ressourcen wie Namespace-Ressourcen und Low-Level-Ressourcen, wie Knoten und persistentVolumes, befinden sich jedoch nicht in einem Namespace. Um zu sehen, welche Kubernetes-Ressourcen sich in einem Namespace befinden und welche nicht:
kubectl api-resources --namespaced=true #In einem Namespace kubectl api-resources --namespaced=false #Nicht in einem Namespace
Sie können den Namespace für alle nachfolgenden kubectl-Befehle in diesem Kontext speichern.
kubectl config set-context --current --namespace=<insert-namespace-name-here>
Helm
Helm ist der Paketmanager für Kubernetes. Er ermöglicht das Verpacken von YAML-Dateien und deren Verteilung in öffentlichen und privaten Repositories. Diese Pakete werden Helm Charts genannt.
helm search <keyword>
Helm ist auch eine Template-Engine, die es ermöglicht, Konfigurationsdateien mit Variablen zu generieren:
Kubernetes Secrets
Ein Secret ist ein Objekt, das sensible Daten wie ein Passwort, ein Token oder einen Schlüssel enthält. Solche Informationen könnten andernfalls in einer Pod-Spezifikation oder in einem Image platziert werden. Benutzer können Secrets erstellen und das System erstellt ebenfalls Secrets. Der Name eines Secret-Objekts muss ein gültiger DNS-Subdomänenname sein. Lesen Sie hier die offizielle Dokumentation.
Secrets können Dinge wie Folgendes sein:
- API-, SSH-Schlüssel.
- OAuth-Token.
- Anmeldeinformationen, Passwörter (im Klartext oder b64 + Verschlüsselung).
- Informationen oder Kommentare.
- Datenbankverbindungs-Code, Strings… .
Es gibt verschiedene Arten von Secrets in Kubernetes
| Eingebauter Typ | Verwendung |
|---|---|
| Opaque | willkürliche benutzerdefinierte Daten (Standard) |
| kubernetes.io/service-account-token | Token des Dienstkontos |
| kubernetes.io/dockercfg | serialisierte ~/.dockercfg-Datei |
| kubernetes.io/dockerconfigjson | serialisierte ~/.docker/config.json-Datei |
| kubernetes.io/basic-auth | Anmeldeinformationen für die grundlegende Authentifizierung |
| kubernetes.io/ssh-auth | Anmeldeinformationen für die SSH-Authentifizierung |
| kubernetes.io/tls | Daten für einen TLS-Client oder -Server |
| bootstrap.kubernetes.io/token | Bootstrap-Token-Daten |
Note
Der Opaque-Typ ist der Standardtyp, das typische Schlüssel-Wert-Paar, das von Benutzern definiert wird.
Wie Secrets funktionieren:
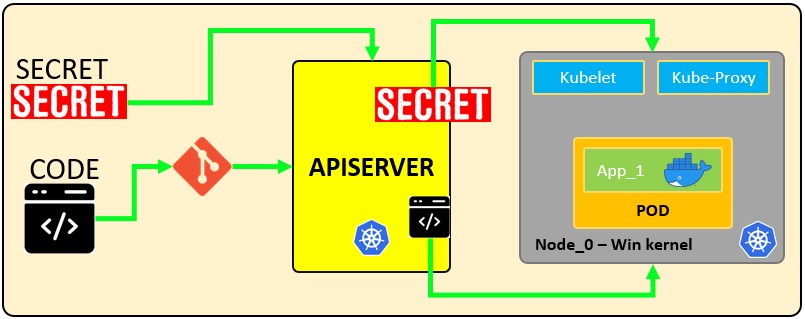
Die folgende Konfigurationsdatei definiert ein Secret namens mysecret mit 2 Schlüssel-Wert-Paaren username: YWRtaW4= und password: MWYyZDFlMmU2N2Rm. Sie definiert auch ein Pod namens secretpod, das die in mysecret definierten username und password in den Umgebungsvariablen SECRET_USERNAME __ und __ SECRET_PASSWOR verfügbar macht. Es wird auch das username-Secret innerhalb von mysecret im Pfad /etc/foo/my-group/my-username mit 0640 Berechtigungen einbinden.
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
username: YWRtaW4=
password: MWYyZDFlMmU2N2Rm
---
apiVersion: v1
kind: Pod
metadata:
name: secretpod
spec:
containers:
- name: secretpod
image: nginx
env:
- name: SECRET_USERNAME
valueFrom:
secretKeyRef:
name: mysecret
key: username
- name: SECRET_PASSWORD
valueFrom:
secretKeyRef:
name: mysecret
key: password
volumeMounts:
- name: foo
mountPath: "/etc/foo"
restartPolicy: Never
volumes:
- name: foo
secret:
secretName: mysecret
items:
- key: username
path: my-group/my-username
mode: 0640
kubectl apply -f <secretpod.yaml>
kubectl get pods #Wait until the pod secretpod is running
kubectl exec -it secretpod -- bash
env | grep SECRET && cat /etc/foo/my-group/my-username && echo
Secrets in etcd
etcd ist ein konsistenter und hochverfügbarer Key-Value-Speicher, der als Kubernetes-Backend-Speicher für alle Cluster-Daten verwendet wird. Lassen Sie uns auf die in etcd gespeicherten Geheimnisse zugreifen:
cat /etc/kubernetes/manifests/kube-apiserver.yaml | grep etcd
Sie werden sehen, dass Zertifikate, Schlüssel und URLs im Dateisystem (FS) gespeichert sind. Sobald Sie diese haben, können Sie sich mit etcd verbinden.
#ETCDCTL_API=3 etcdctl --cert <path to client.crt> --key <path to client.ket> --cacert <path to CA.cert> endpoint=[<ip:port>] health
ETCDCTL_API=3 etcdctl --cert /etc/kubernetes/pki/apiserver-etcd-client.crt --key /etc/kubernetes/pki/apiserver-etcd-client.key --cacert /etc/kubernetes/pki/etcd/etcd/ca.cert endpoint=[127.0.0.1:1234] health
Sobald Sie die Kommunikation hergestellt haben, können Sie die Geheimnisse erhalten:
#ETCDCTL_API=3 etcdctl --cert <path to client.crt> --key <path to client.ket> --cacert <path to CA.cert> endpoint=[<ip:port>] get <path/to/secret>
ETCDCTL_API=3 etcdctl --cert /etc/kubernetes/pki/apiserver-etcd-client.crt --key /etc/kubernetes/pki/apiserver-etcd-client.key --cacert /etc/kubernetes/pki/etcd/etcd/ca.cert endpoint=[127.0.0.1:1234] get /registry/secrets/default/secret_02
Verschlüsselung zum ETCD hinzufügen
Standardmäßig werden alle Geheimnisse im Klartext in etcd gespeichert, es sei denn, Sie wenden eine Verschlüsselungsschicht an. Das folgende Beispiel basiert auf https://kubernetes.io/docs/tasks/administer-cluster/encrypt-data/
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
providers:
- aescbc:
keys:
- name: key1
secret: cjjPMcWpTPKhAdieVtd+KhG4NN+N6e3NmBPMXJvbfrY= #Any random key
- identity: {}
Danach müssen Sie das Flag --encryption-provider-config auf dem kube-apiserver setzen, um auf den Speicherort der erstellten Konfigurationsdatei zu verweisen. Sie können /etc/kubernetes/manifest/kube-apiserver.yaml bearbeiten und die folgenden Zeilen hinzufügen:
containers:
- command:
- kube-apiserver
- --encriyption-provider-config=/etc/kubernetes/etcd/<configFile.yaml>
Scrollen Sie nach unten in den volumeMounts:
- mountPath: /etc/kubernetes/etcd
name: etcd
readOnly: true
Scrollen Sie nach unten in den volumeMounts zu hostPath:
- hostPath:
path: /etc/kubernetes/etcd
type: DirectoryOrCreate
name: etcd
Überprüfung, dass Daten verschlüsselt sind
Daten werden verschlüsselt, wenn sie in etcd geschrieben werden. Nach dem Neustart Ihres kube-apiserver sollte jedes neu erstellte oder aktualisierte Secret verschlüsselt gespeichert werden. Um dies zu überprüfen, können Sie das etcdctl-Befehlszeilenprogramm verwenden, um den Inhalt Ihres Secrets abzurufen.
- Erstellen Sie ein neues Secret mit dem Namen
secret1imdefault-Namespace:
kubectl create secret generic secret1 -n default --from-literal=mykey=mydata
- Lesen Sie dieses Secret mit dem etcdctl-Befehlszeilenprogramm aus etcd:
ETCDCTL_API=3 etcdctl get /registry/secrets/default/secret1 [...] | hexdump -C
wobei [...] die zusätzlichen Argumente für die Verbindung zum etcd-Server sein müssen.
- Überprüfen Sie, ob das gespeicherte Secret mit
k8s:enc:aescbc:v1:vorangestellt ist, was darauf hinweist, dass deraescbc-Provider die resultierenden Daten verschlüsselt hat. - Überprüfen Sie, ob das Secret korrekt entschlüsselt wird, wenn es über die API abgerufen wird:
kubectl describe secret secret1 -n default
sollte mykey: bXlkYXRh entsprechen, mydata ist kodiert, überprüfen Sie decoding a secret, um das Secret vollständig zu dekodieren.
Da Secrets beim Schreiben verschlüsselt werden, wird das Aktualisieren eines Secrets diesen Inhalt verschlüsseln:
kubectl get secrets --all-namespaces -o json | kubectl replace -f -
Abschließende Tipps:
- Versuche, keine Geheimnisse im FS zu speichern, hole sie aus anderen Quellen.
- Schau dir https://www.vaultproject.io/ an, um zusätzlichen Schutz für deine Geheimnisse zu erhalten.
- https://kubernetes.io/docs/concepts/configuration/secret/#risks
- https://docs.cyberark.com/Product-Doc/OnlineHelp/AAM-DAP/11.2/en/Content/Integrations/Kubernetes_deployApplicationsConjur-k8s-Secrets.htm
Referenzen
kubesectips v1 | sickrov.github.io
Tip
Lerne & übe AWS Hacking:
Lerne & übe GCP Hacking:
Lerne & übe Az Hacking:Unterstütze HackTricks
- Sieh dir die Abonnementpläne an!
- Tritt der 💬 Discord group oder der telegram group bei oder folge uns auf Twitter 🐦 @hacktricks_live.
- Teile Hacking-Tricks, indem du PRs an die HackTricks und HackTricks Cloud GitHub-Repos einreichst.