Kubernetes Basics
Tip
Ucz się & ćwicz AWS Hacking:
HackTricks Training AWS Red Team Expert (ARTE)
Ucz się & ćwicz GCP Hacking:HackTricks Training GCP Red Team Expert (GRTE)
Ucz się & ćwicz Az Hacking:HackTricks Training Azure Red Team Expert (AzRTE)
Wspieraj HackTricks
- Sprawdź subscription plans!
- Dołącz do 💬 Discord group lub telegram group lub śledź nas na Twitterze 🐦 @hacktricks_live.
- Podziel się hacking tricks, zgłaszając PRy do HackTricks i HackTricks Cloud github repos.
Oryginalnym autorem tej strony jest Jorge (przeczytaj jego oryginalny post tutaj)
Architektura i podstawy
Co robi Kubernetes?
- Umożliwia uruchamianie kontenerów w silniku kontenerowym.
- Harmonogram pozwala na efektywne planowanie misji kontenerów.
- Utrzymuje kontenery przy życiu.
- Umożliwia komunikację między kontenerami.
- Umożliwia techniki wdrażania.
- Obsługuje wolumeny informacji.
Architektura
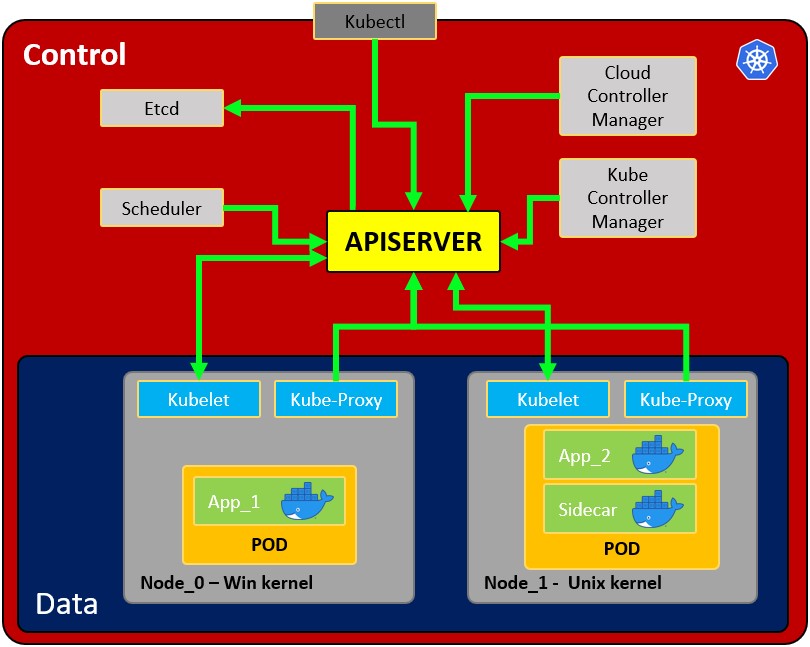
- Węzeł: system operacyjny z podami.
- Pod: opakowanie wokół kontenera lub wielu kontenerów. Pod powinien zawierać tylko jedną aplikację (zazwyczaj pod uruchamia tylko 1 kontener). Pod to sposób, w jaki Kubernetes abstrahuje technologię kontenerową.
- Usługa: Każdy pod ma 1 wewnętrzny adres IP z wewnętrznego zakresu węzła. Może być również udostępniony za pośrednictwem usługi. Usługa ma również adres IP i jej celem jest utrzymanie komunikacji między podami, więc jeśli jeden z nich zginie, nowy zamiennik (z innym wewnętrznym IP) będzie dostępny pod tym samym adresem IP usługi. Może być skonfigurowana jako wewnętrzna lub zewnętrzna. Usługa działa również jako load balancer, gdy 2 pody są połączone z tą samą usługą.
Gdy usługa jest tworzona, możesz znaleźć punkty końcowe każdej usługi uruchamiająckubectl get endpoints - Kubelet: Główny agent węzła. Komponent, który nawiązuje komunikację między węzłem a kubectl, i może uruchamiać tylko pody (przez API server). Kubelet nie zarządza kontenerami, które nie zostały utworzone przez Kubernetes.
- Kube-proxy: jest usługą odpowiedzialną za komunikację (usługi) między apiserver a węzłem. Podstawą jest IPtables dla węzłów. Najbardziej doświadczeni użytkownicy mogą zainstalować inne kube-proxy od innych dostawców.
- Kontener sidecar: Kontenery sidecar to kontenery, które powinny działać razem z głównym kontenerem w podzie. Wzorzec sidecar rozszerza i poprawia funkcjonalność obecnych kontenerów bez ich zmiany. Obecnie wiemy, że używamy technologii kontenerowej do opakowania wszystkich zależności, aby aplikacja mogła działać wszędzie. Kontener robi tylko jedną rzecz i robi to bardzo dobrze.
- Proces główny:
- Api Server: To sposób, w jaki użytkownicy i pody komunikują się z procesem głównym. Tylko uwierzytelnione żądania powinny być dozwolone.
- Harmonogram: Harmonogram odnosi się do zapewnienia, że pody są dopasowane do węzłów, aby Kubelet mógł je uruchomić. Ma wystarczającą inteligencję, aby zdecydować, który węzeł ma więcej dostępnych zasobów, a następnie przypisać nowy pod do niego. Należy zauważyć, że harmonogram nie uruchamia nowych podów, tylko komunikuje się z procesem Kubelet działającym wewnątrz węzła, który uruchomi nowy pod.
- Kube Controller manager: Sprawdza zasoby, takie jak zestawy replik lub wdrożenia, aby sprawdzić, czy na przykład działa odpowiednia liczba podów lub węzłów. W przypadku braku poda skomunikuje się z harmonogramem, aby uruchomić nowy. Kontroluje replikację, tokeny i usługi konta do API.
- etcd: Przechowywanie danych, trwałe, spójne i rozproszone. Jest bazą danych Kubernetes i przechowuje stan klastrów (każda zmiana jest tutaj rejestrowana). Komponenty, takie jak Harmonogram czy Menedżer Kontrolera, polegają na tych danych, aby wiedzieć, jakie zmiany zaszły (dostępne zasoby węzłów, liczba działających podów…)
- Cloud controller manager: Jest to specyficzny kontroler do zarządzania przepływem i aplikacjami, tzn. jeśli masz klastry w AWS lub OpenStack.
Należy zauważyć, że ponieważ może być kilka węzłów (uruchamiających kilka podów), może być również kilka procesów głównych, których dostęp do Api server jest równoważony obciążeniem, a ich etcd synchronizowane.
Wolumeny:
Gdy pod tworzy dane, które nie powinny zostać utracone po zniknięciu poda, powinny być przechowywane w fizycznym wolumenie. Kubernetes pozwala na podłączenie wolumenu do poda, aby zachować dane. Wolumen może znajdować się na lokalnej maszynie lub w zdalnym magazynie. Jeśli uruchamiasz pody na różnych fizycznych węzłach, powinieneś użyć zdalnego magazynu, aby wszystkie pody mogły uzyskać do niego dostęp.
Inne konfiguracje:
- ConfigMap: Możesz skonfigurować URL do uzyskiwania dostępu do usług. Pod uzyska dane stąd, aby wiedzieć, jak komunikować się z pozostałymi usługami (podami). Należy zauważyć, że to nie jest zalecane miejsce do przechowywania poświadczeń!
- Secret: To jest miejsce do przechowywania tajnych danych takich jak hasła, klucze API… zakodowane w B64. Pod będzie mógł uzyskać dostęp do tych danych, aby użyć wymaganych poświadczeń.
- Wdrożenia: To tutaj wskazuje się komponenty, które mają być uruchamiane przez Kubernetes. Użytkownik zazwyczaj nie pracuje bezpośrednio z podami, pody są abstrakowane w ReplicaSets (liczba tych samych podów replikowanych), które są uruchamiane za pomocą wdrożeń. Należy zauważyć, że wdrożenia są dla aplikacji bezstanowych. Minimalna konfiguracja dla wdrożenia to nazwa i obraz do uruchomienia.
- StatefulSet: Ten komponent jest przeznaczony specjalnie dla aplikacji takich jak bazy danych, które muszą uzyskiwać dostęp do tego samego magazynu.
- Ingress: To jest konfiguracja, która jest używana do publicznego udostępnienia aplikacji za pomocą URL. Należy zauważyć, że można to również zrobić za pomocą zewnętrznych usług, ale to jest poprawny sposób na udostępnienie aplikacji.
- Jeśli wdrożysz Ingress, będziesz musiał utworzyć Ingress Controllers. Kontroler Ingress to pod, który będzie punktem końcowym, który otrzyma żądania, sprawdzi je i zrównoważy obciążenie do usług. Kontroler ingress wyśle żądanie na podstawie skonfigurowanych reguł ingress. Należy zauważyć, że reguły ingress mogą wskazywać na różne ścieżki lub nawet subdomeny do różnych wewnętrznych usług Kubernetes.
- Lepszą praktyką bezpieczeństwa byłoby użycie chmurowego load balancera lub serwera proxy jako punktu wejścia, aby żadna część klastra Kubernetes nie była wystawiona.
- Gdy otrzymane zostanie żądanie, które nie pasuje do żadnej reguły ingress, kontroler ingress skieruje je do “Domyślnego backendu”. Możesz
describekontroler ingress, aby uzyskać adres tego parametru. minikube addons enable ingress
Infrastruktura PKI - Certyfikacja CA:
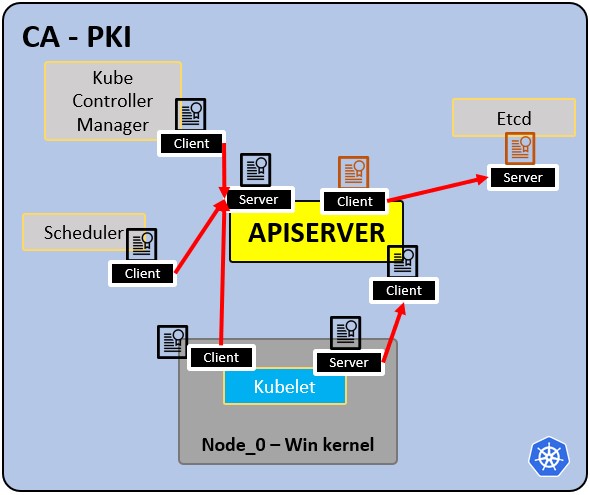
- CA jest zaufanym korzeniem dla wszystkich certyfikatów w klastrze.
- Umożliwia komponentom wzajemną weryfikację.
- Wszystkie certyfikaty klastra są podpisane przez CA.
- ETCd ma swój własny certyfikat.
- typy:
- certyfikat apiserver.
- certyfikat kubelet.
- certyfikat harmonogramu.
Podstawowe działania
Minikube
Minikube może być używany do przeprowadzania kilku szybkich testów na Kubernetes bez potrzeby wdrażania całego środowiska Kubernetes. Uruchomi procesy główne i węzłowe na jednej maszynie. Minikube użyje virtualbox do uruchomienia węzła. Zobacz tutaj, jak to zainstalować.
$ minikube start
😄 minikube v1.19.0 on Ubuntu 20.04
✨ Automatically selected the virtualbox driver. Other choices: none, ssh
💿 Downloading VM boot image ...
> minikube-v1.19.0.iso.sha256: 65 B / 65 B [-------------] 100.00% ? p/s 0s
> minikube-v1.19.0.iso: 244.49 MiB / 244.49 MiB 100.00% 1.78 MiB p/s 2m17.
👍 Starting control plane node minikube in cluster minikube
💾 Downloading Kubernetes v1.20.2 preload ...
> preloaded-images-k8s-v10-v1...: 491.71 MiB / 491.71 MiB 100.00% 2.59 MiB
🔥 Creating virtualbox VM (CPUs=2, Memory=3900MB, Disk=20000MB) ...
🐳 Preparing Kubernetes v1.20.2 on Docker 20.10.4 ...
▪ Generating certificates and keys ...
▪ Booting up control plane ...
▪ Configuring RBAC rules ...
🔎 Verifying Kubernetes components...
▪ Using image gcr.io/k8s-minikube/storage-provisioner:v5
🌟 Enabled addons: storage-provisioner, default-storageclass
🏄 Done! kubectl is now configured to use "minikube" cluster and "default" namespace by defaul
$ minikube status
host: Running
kubelet: Running
apiserver: Running
kubeconfig: Configured
---- ONCE YOU HAVE A K8 SERVICE RUNNING WITH AN EXTERNAL SERVICE -----
$ minikube service mongo-express-service
(This will open your browser to access the service exposed port)
$ minikube delete
🔥 Deleting "minikube" in virtualbox ...
💀 Removed all traces of the "minikube" cluster
Kubectl Podstawy
Kubectl to narzędzie wiersza poleceń dla klastrów kubernetes. Komunikuje się z serwerem Api procesu głównego, aby wykonywać akcje w kubernetes lub prosić o dane.
kubectl version #Get client and server version
kubectl get pod
kubectl get services
kubectl get deployment
kubectl get replicaset
kubectl get secret
kubectl get all
kubectl get ingress
kubectl get endpoints
#kubectl create deployment <deployment-name> --image=<docker image>
kubectl create deployment nginx-deployment --image=nginx
#Access the configuration of the deployment and modify it
#kubectl edit deployment <deployment-name>
kubectl edit deployment nginx-deployment
#Get the logs of the pod for debbugging (the output of the docker container running)
#kubectl logs <replicaset-id/pod-id>
kubectl logs nginx-deployment-84cd76b964
#kubectl describe pod <pod-id>
kubectl describe pod mongo-depl-5fd6b7d4b4-kkt9q
#kubectl exec -it <pod-id> -- bash
kubectl exec -it mongo-depl-5fd6b7d4b4-kkt9q -- bash
#kubectl describe service <service-name>
kubectl describe service mongodb-service
#kubectl delete deployment <deployment-name>
kubectl delete deployment mongo-depl
#Deploy from config file
kubectl apply -f deployment.yml
Minikube Dashboard
Panel sterowania pozwala łatwiej zobaczyć, co uruchamia minikube, możesz znaleźć URL do jego dostępu w:
minikube dashboard --url
🔌 Enabling dashboard ...
▪ Using image kubernetesui/dashboard:v2.3.1
▪ Using image kubernetesui/metrics-scraper:v1.0.7
🤔 Verifying dashboard health ...
🚀 Launching proxy ...
🤔 Verifying proxy health ...
http://127.0.0.1:50034/api/v1/namespaces/kubernetes-dashboard/services/http:kubernetes-dashboard:/proxy/
Przykłady plików konfiguracyjnych YAML
Każdy plik konfiguracyjny ma 3 części: metadane, specyfikacja (co należy uruchomić), status (pożądany stan).
Wewnątrz specyfikacji pliku konfiguracyjnego wdrożenia można znaleźć szablon zdefiniowany z nową strukturą konfiguracyjną definiującą obraz do uruchomienia:
Przykład Wdrożenia + Usługi zadeklarowanej w tym samym pliku konfiguracyjnym (z tutaj)
Ponieważ usługa zazwyczaj jest związana z jednym wdrożeniem, możliwe jest zadeklarowanie obu w tym samym pliku konfiguracyjnym (usługa zadeklarowana w tej konfiguracji jest dostępna tylko wewnętrznie):
apiVersion: apps/v1
kind: Deployment
metadata:
name: mongodb-deployment
labels:
app: mongodb
spec:
replicas: 1
selector:
matchLabels:
app: mongodb
template:
metadata:
labels:
app: mongodb
spec:
containers:
- name: mongodb
image: mongo
ports:
- containerPort: 27017
env:
- name: MONGO_INITDB_ROOT_USERNAME
valueFrom:
secretKeyRef:
name: mongodb-secret
key: mongo-root-username
- name: MONGO_INITDB_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mongodb-secret
key: mongo-root-password
---
apiVersion: v1
kind: Service
metadata:
name: mongodb-service
spec:
selector:
app: mongodb
ports:
- protocol: TCP
port: 27017
targetPort: 27017
Przykład konfiguracji usługi zewnętrznej
Ta usługa będzie dostępna zewnętrznie (sprawdź atrybuty nodePort i type: LoadBlancer):
---
apiVersion: v1
kind: Service
metadata:
name: mongo-express-service
spec:
selector:
app: mongo-express
type: LoadBalancer
ports:
- protocol: TCP
port: 8081
targetPort: 8081
nodePort: 30000
Note
To jest przydatne do testowania, ale w produkcji powinieneś mieć tylko usługi wewnętrzne i Ingress, aby udostępnić aplikację.
Przykład pliku konfiguracyjnego Ingress
To udostępni aplikację pod adresem http://dashboard.com.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: dashboard-ingress
namespace: kubernetes-dashboard
spec:
rules:
- host: dashboard.com
http:
paths:
- backend:
serviceName: kubernetes-dashboard
servicePort: 80
Przykład pliku konfiguracyjnego z sekretami
Zauważ, że hasła są zakodowane w B64 (co nie jest bezpieczne!)
apiVersion: v1
kind: Secret
metadata:
name: mongodb-secret
type: Opaque
data:
mongo-root-username: dXNlcm5hbWU=
mongo-root-password: cGFzc3dvcmQ=
Przykład ConfigMap
A ConfigMap to konfiguracja, która jest przekazywana do podów, aby wiedziały, jak lokalizować i uzyskiwać dostęp do innych usług. W tym przypadku każdy pod będzie wiedział, że nazwa mongodb-service to adres poda, z którym mogą się komunikować (ten pod będzie wykonywał mongodb):
apiVersion: v1
kind: ConfigMap
metadata:
name: mongodb-configmap
data:
database_url: mongodb-service
Następnie, wewnątrz deployment config ten adres może być określony w następujący sposób, aby został załadowany do env pod:
[...]
spec:
[...]
template:
[...]
spec:
containers:
- name: mongo-express
image: mongo-express
ports:
- containerPort: 8081
env:
- name: ME_CONFIG_MONGODB_SERVER
valueFrom:
configMapKeyRef:
name: mongodb-configmap
key: database_url
[...]
Przykład konfiguracji wolumenu
Możesz znaleźć różne przykłady plików konfiguracyjnych storage w formacie yaml w https://gitlab.com/nanuchi/youtube-tutorial-series/-/tree/master/kubernetes-volumes.
Zauważ, że wolumeny nie znajdują się w przestrzeniach nazw
Przestrzenie nazw
Kubernetes obsługuje wiele wirtualnych klastrów opartych na tym samym fizycznym klastrze. Te wirtualne klastry nazywane są przestrzeniami nazw. Są one przeznaczone do użytku w środowiskach z wieloma użytkownikami rozproszonymi w różnych zespołach lub projektach. W przypadku klastrów z kilkoma do kilkunastu użytkowników, nie powinieneś w ogóle tworzyć ani myśleć o przestrzeniach nazw. Powinieneś zacząć używać przestrzeni nazw, aby lepiej kontrolować i organizować każdą część aplikacji wdrożonej w kubernetes.
Przestrzenie nazw zapewniają zakres dla nazw. Nazwy zasobów muszą być unikalne w obrębie przestrzeni nazw, ale nie w różnych przestrzeniach nazw. Przestrzenie nazw nie mogą być zagnieżdżane w sobie nawzajem, a każdy zasób Kubernetes może być tylko w jednej przestrzeni nazw.
Domyślnie są 4 przestrzenie nazw, jeśli używasz minikube:
kubectl get namespace
NAME STATUS AGE
default Active 1d
kube-node-lease Active 1d
kube-public Active 1d
kube-system Active 1d
- kube-system: Nie jest przeznaczony do użytku przez użytkowników i nie powinieneś go dotykać. Jest to przestrzeń dla procesów master i kubectl.
- kube-public: Publicznie dostępne dane. Zawiera configmap, który zawiera informacje o klastrze.
- kube-node-lease: Określa dostępność węzła.
- default: Przestrzeń nazw, której użytkownik użyje do tworzenia zasobów.
#Create namespace
kubectl create namespace my-namespace
Note
Zauważ, że większość zasobów Kubernetes (np. pods, services, replication controllers i inne) znajduje się w pewnych przestrzeniach nazw. Jednak inne zasoby, takie jak zasoby przestrzeni nazw i zasoby niskiego poziomu, takie jak nodes i persistentVolumes, nie są w przestrzeni nazw. Aby zobaczyć, które zasoby Kubernetes są i nie są w przestrzeni nazw:
kubectl api-resources --namespaced=true #W przestrzeni nazw kubectl api-resources --namespaced=false #Nie w przestrzeni nazw
Możesz zapisać przestrzeń nazw dla wszystkich kolejnych poleceń kubectl w tym kontekście.
kubectl config set-context --current --namespace=<insert-namespace-name-here>
Helm
Helm to menedżer pakietów dla Kubernetes. Umożliwia pakowanie plików YAML i dystrybucję ich w publicznych i prywatnych repozytoriach. Te pakiety nazywane są Helm Charts.
helm search <keyword>
Helm jest również silnikiem szablonów, który pozwala na generowanie plików konfiguracyjnych z zmiennymi:
Kubernetes secrets
Secret to obiekt, który zawiera wrażliwe dane, takie jak hasło, token lub klucz. Takie informacje mogłyby być umieszczone w specyfikacji Pod lub w obrazie. Użytkownicy mogą tworzyć Secrets, a system również tworzy Secrets. Nazwa obiektu Secret musi być ważną nazwą subdomeny DNS. Przeczytaj tutaj oficjalną dokumentację.
Secrets mogą być takie jak:
- Klucze API, SSH.
- Tokeny OAuth.
- Poświadczenia, Hasła (tekst jawny lub b64 + szyfrowanie).
- Informacje lub komentarze.
- Kod połączenia z bazą danych, ciągi… .
Istnieją różne typy sekretów w Kubernetes
| Typ wbudowany | Użycie |
|---|---|
| Opaque | dowolne dane zdefiniowane przez użytkownika (Domyślnie) |
| kubernetes.io/service-account-token | token konta usługi |
| kubernetes.io/dockercfg | zserializowany plik ~/.dockercfg |
| kubernetes.io/dockerconfigjson | zserializowany plik ~/.docker/config.json |
| kubernetes.io/basic-auth | poświadczenia do podstawowej autoryzacji |
| kubernetes.io/ssh-auth | poświadczenia do autoryzacji SSH |
| kubernetes.io/tls | dane dla klienta lub serwera TLS |
| bootstrap.kubernetes.io/token | dane tokena bootstrap |
Note
Typ Opaque jest domyślnym typem, typową parą klucz-wartość zdefiniowaną przez użytkowników.
Jak działają sekrety:
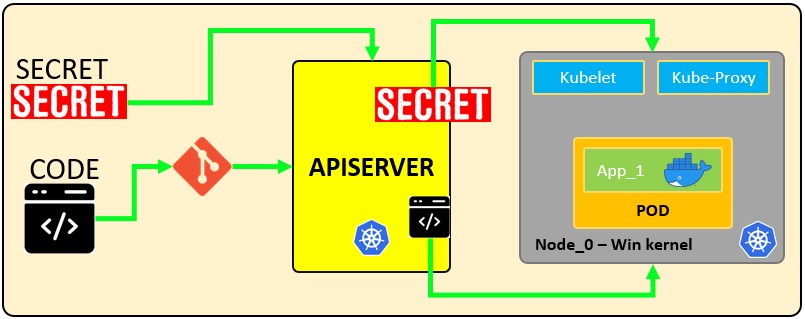
Poniższy plik konfiguracyjny definiuje secret o nazwie mysecret z 2 parami klucz-wartość username: YWRtaW4= i password: MWYyZDFlMmU2N2Rm. Definiuje również pod o nazwie secretpod, który będzie miał username i password zdefiniowane w mysecret wystawione w zmiennych środowiskowych SECRET_USERNAME __ i __ SECRET_PASSWOR. Będzie również montować sekret username wewnątrz mysecret w ścieżce /etc/foo/my-group/my-username z uprawnieniami 0640.
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
username: YWRtaW4=
password: MWYyZDFlMmU2N2Rm
---
apiVersion: v1
kind: Pod
metadata:
name: secretpod
spec:
containers:
- name: secretpod
image: nginx
env:
- name: SECRET_USERNAME
valueFrom:
secretKeyRef:
name: mysecret
key: username
- name: SECRET_PASSWORD
valueFrom:
secretKeyRef:
name: mysecret
key: password
volumeMounts:
- name: foo
mountPath: "/etc/foo"
restartPolicy: Never
volumes:
- name: foo
secret:
secretName: mysecret
items:
- key: username
path: my-group/my-username
mode: 0640
kubectl apply -f <secretpod.yaml>
kubectl get pods #Wait until the pod secretpod is running
kubectl exec -it secretpod -- bash
env | grep SECRET && cat /etc/foo/my-group/my-username && echo
Sekrety w etcd
etcd to spójny i wysoce dostępny magazyn klucz-wartość używany jako zaplecze Kubernetes dla wszystkich danych klastra. Uzyskajmy dostęp do sekretów przechowywanych w etcd:
cat /etc/kubernetes/manifests/kube-apiserver.yaml | grep etcd
Zobaczysz certy, klucze i adresy URL, które znajdują się w systemie plików. Gdy je zdobędziesz, będziesz mógł połączyć się z etcd.
#ETCDCTL_API=3 etcdctl --cert <path to client.crt> --key <path to client.ket> --cacert <path to CA.cert> endpoint=[<ip:port>] health
ETCDCTL_API=3 etcdctl --cert /etc/kubernetes/pki/apiserver-etcd-client.crt --key /etc/kubernetes/pki/apiserver-etcd-client.key --cacert /etc/kubernetes/pki/etcd/etcd/ca.cert endpoint=[127.0.0.1:1234] health
Gdy nawiążesz komunikację, będziesz w stanie uzyskać sekrety:
#ETCDCTL_API=3 etcdctl --cert <path to client.crt> --key <path to client.ket> --cacert <path to CA.cert> endpoint=[<ip:port>] get <path/to/secret>
ETCDCTL_API=3 etcdctl --cert /etc/kubernetes/pki/apiserver-etcd-client.crt --key /etc/kubernetes/pki/apiserver-etcd-client.key --cacert /etc/kubernetes/pki/etcd/etcd/ca.cert endpoint=[127.0.0.1:1234] get /registry/secrets/default/secret_02
Dodawanie szyfrowania do ETCD
Domyślnie wszystkie sekrety są przechowywane w postaci niezaszyfrowanej w etcd, chyba że zastosujesz warstwę szyfrowania. Poniższy przykład oparty jest na https://kubernetes.io/docs/tasks/administer-cluster/encrypt-data/
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
providers:
- aescbc:
keys:
- name: key1
secret: cjjPMcWpTPKhAdieVtd+KhG4NN+N6e3NmBPMXJvbfrY= #Any random key
- identity: {}
Po tym musisz ustawić flagę --encryption-provider-config na kube-apiserver, aby wskazywała na lokalizację utworzonego pliku konfiguracyjnego. Możesz zmodyfikować /etc/kubernetes/manifest/kube-apiserver.yaml i dodać następujące linie:
containers:
- command:
- kube-apiserver
- --encriyption-provider-config=/etc/kubernetes/etcd/<configFile.yaml>
Przewiń w dół w volumeMounts:
- mountPath: /etc/kubernetes/etcd
name: etcd
readOnly: true
Przewiń w dół w volumeMounts do hostPath:
- hostPath:
path: /etc/kubernetes/etcd
type: DirectoryOrCreate
name: etcd
Weryfikacja, że dane są zaszyfrowane
Dane są zaszyfrowane podczas zapisywania do etcd. Po ponownym uruchomieniu kube-apiserver, każdy nowo utworzony lub zaktualizowany sekret powinien być zaszyfrowany podczas przechowywania. Aby to sprawdzić, możesz użyć programu wiersza poleceń etcdctl, aby pobrać zawartość swojego sekretu.
- Utwórz nowy sekret o nazwie
secret1w przestrzeni nazwdefault:
kubectl create secret generic secret1 -n default --from-literal=mykey=mydata
- Używając wiersza poleceń etcdctl, odczytaj ten sekret z etcd:
ETCDCTL_API=3 etcdctl get /registry/secrets/default/secret1 [...] | hexdump -C
gdzie [...] musi być dodatkowymi argumentami do połączenia z serwerem etcd.
- Zweryfikuj, że przechowywany sekret jest poprzedzony prefiksem
k8s:enc:aescbc:v1:, co wskazuje, że dostawcaaescbczaszyfrował wynikowe dane. - Zweryfikuj, że sekret jest poprawnie odszyfrowany podczas pobierania przez API:
kubectl describe secret secret1 -n default
powinno odpowiadać mykey: bXlkYXRh, mydata jest zakodowane, sprawdź dekodowanie sekretu, aby całkowicie odszyfrować sekret.
Ponieważ sekrety są szyfrowane podczas zapisu, wykonanie aktualizacji sekretnych zaszyfruje tę zawartość:
kubectl get secrets --all-namespaces -o json | kubectl replace -f -
Ostateczne wskazówki:
- Staraj się nie przechowywać sekretów w FS, pozyskuj je z innych miejsc.
- Sprawdź https://www.vaultproject.io/, aby dodać więcej ochrony do swoich sekretów.
- https://kubernetes.io/docs/concepts/configuration/secret/#risks
- https://docs.cyberark.com/Product-Doc/OnlineHelp/AAM-DAP/11.2/en/Content/Integrations/Kubernetes_deployApplicationsConjur-k8s-Secrets.htm
Odniesienia
kubesectips v1 | sickrov.github.io
Tip
Ucz się & ćwicz AWS Hacking:
Ucz się & ćwicz GCP Hacking:
Ucz się & ćwicz Az Hacking:Wspieraj HackTricks
- Sprawdź subscription plans!
- Dołącz do 💬 Discord group lub telegram group lub śledź nas na Twitterze 🐦 @hacktricks_live.
- Podziel się hacking tricks, zgłaszając PRy do HackTricks i HackTricks Cloud github repos.